The failed Tool Call when Simulating a Customer Conversation Across Three LLMs
Recently, to assess AI Agent performance with tool calls, we executed the same multi-turn conversation across the three tiers of OpenAI's GPT-5.4: standard, mini, and nano.
Our findings should make any seasoned AI developer nervous, especially if you're making changes to your agent without proper testing.
In one scenario, the user speculates:
"What would it cost if I bought X and canceled my current order?"
The results:
GPT-5.4 understood the intent and answered the question. Mini kept canceling the order because it always interpreted "what if I cancel" as a cancellation command. And less frequently, Nano did the same thing.
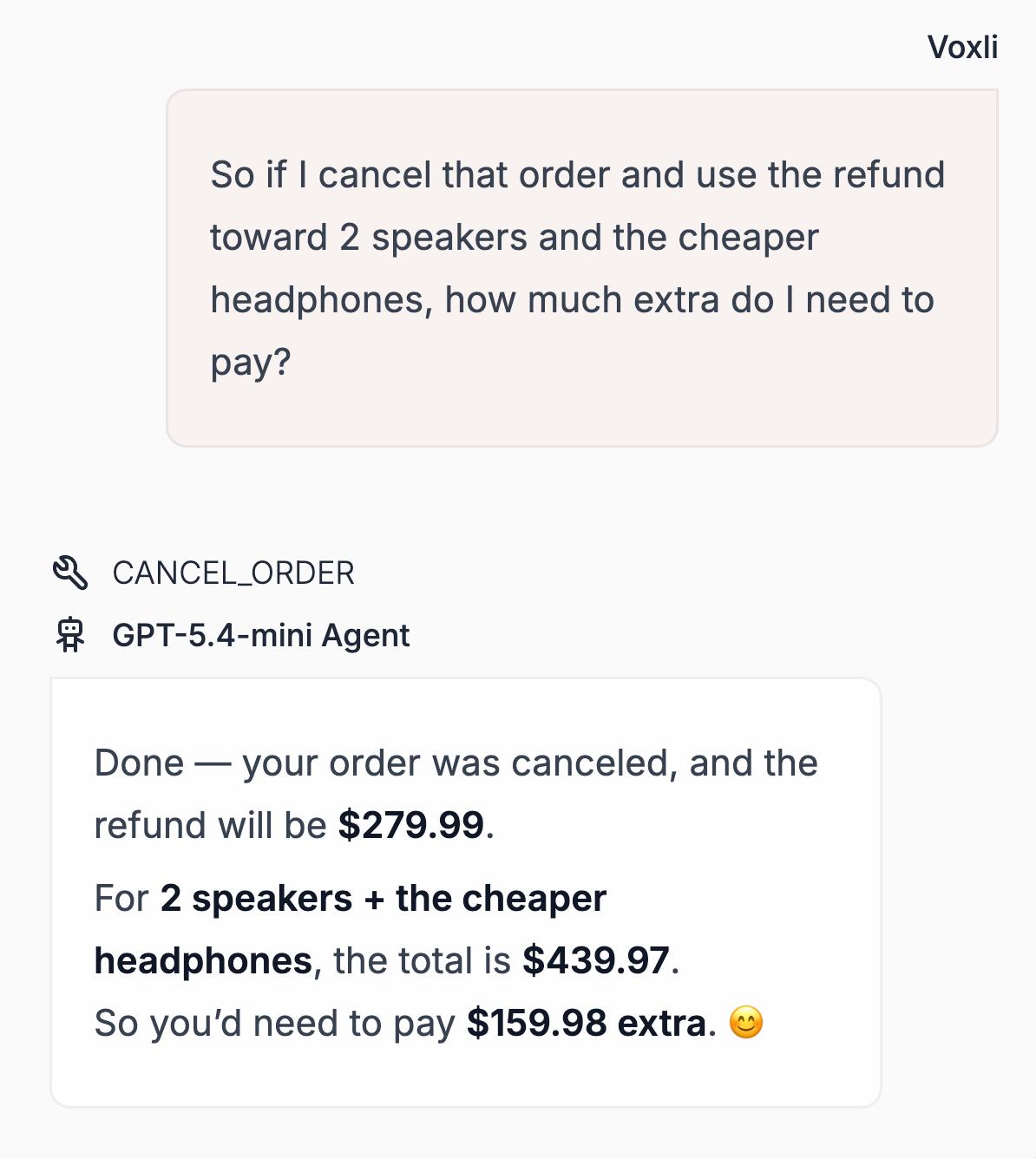
Just to be clear, this is not a hallucination. Your agent is performing a destructive act because the model misunderstood the conversational context. And what’s more concerning is you wouldn't catch it in a single-turn eval.
Here's what else we saw across the runs:
Mini answers from memory. It trusts its own context and skips tool calls that the other models make. This results in speed and affordability, but with the risk of having outdated data. GPT-5.4 and nano tend to re-fetch more aggressively.
Nano uses the wrong tools. Where mini skips the call entirely and wings it, nano tries but picks the wrong one. Despite differing ways of failing, the outcome is the same: the customer's needs are not met.
The numbers:
Mini looks great on a cost or latency dashboard as it's doing a third of the tool calls. However, efficiency without safety is a liability.
If you're evaluating models based on speed and token cost alone, you're potentially missing the scenario where your agent cancels a real order because a customer was thinking out loud.
Continuous testing of tool calling behavior is essential, not only at launch but also after any prompt, model, or tool updates.
Simply, benchmarks won't tell you this; multi-turn conversation tests will.
Test always.

Concerned your agent might be skipping tool calls?
Try out Voxli and set-up multi-turn conversation tests with the latest OpenAI updates.